悲观锁 VS. 乐观锁
在并发编程中,由于多线程同时处理同一数据会发生冲突,需要我们设定机制去解决这个冲突。通常是用锁的方式,锁又可以分成悲观锁和乐观锁。
1.顾名思义,前者是从悲观角度判断当前并发情况,认为多线程处理同一数据极有可能发生冲突。无论是否发生冲突,我们都会给数据前后加锁,组织其他线程修改。
2.后者从乐观角度判断当前并发情况,认为多线程处理同一数据几乎不会发生冲突。先按照预设的不冲突方式去处理数据,如果发现数据已被其他线程修改的话再做额外处理。
通过上面的描述,可以大概明确悲观锁和乐观锁的使用场景。悲观锁适用于冲突概率比较高的环境,乐观锁适用于冲突概率比较低的环境。
因为加锁解锁需要额外的开销,如果数据没有冲突仍加解锁,会多了平白无故的开销。在这样的场景下,乐观锁效率就会高得多。
常见的悲观锁有Synchronized、Lock等,乐观锁主要为CAS。接下去我们讲解下CAS。
CAS
CAS全称为Compare And Swap,直译过来就是比较和替换
适用的类:AtomicInteger,AtomicLong等基础数据类型
先看下AtomicInteger的调用函数1
2
3
4
5
6/*
* expect:期望值
* update:如果当前值等于期望值,则将当前值更新为update
* return:返回是否更新成功
*/
public final boolean compareAndSet(int expect, int update)
这里加入了expect,用来判断当前值是否等于预期值。因为在并发环境下,当前线程记录的值和实际值不一定相同(在之前记录和现在调用cas的间隔中被其他线程修改,而当前线程并不能感知到实际值的变化)。
简单的使用一次compareAndSet并不能完成任务。假设当前线程的任务是将值加一:1
2
3int current = get();
int expect = current + 1;
compareAndSet(current, expect);
因为如果值被其他线程修改,则不会触发更新。常用的操作方式是在外面包裹着循环:1
2
3
4
5
6
7
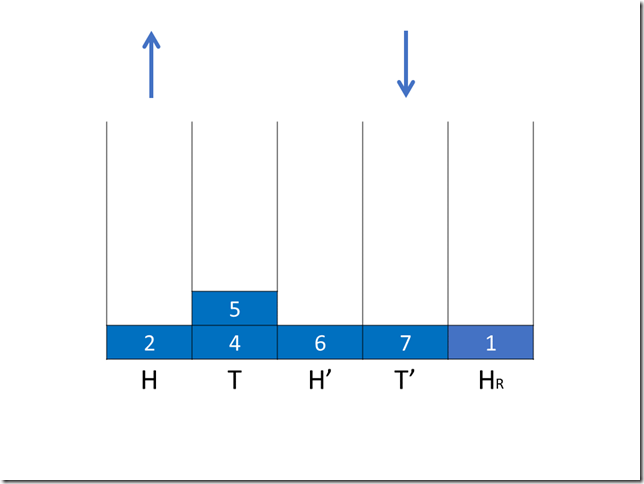
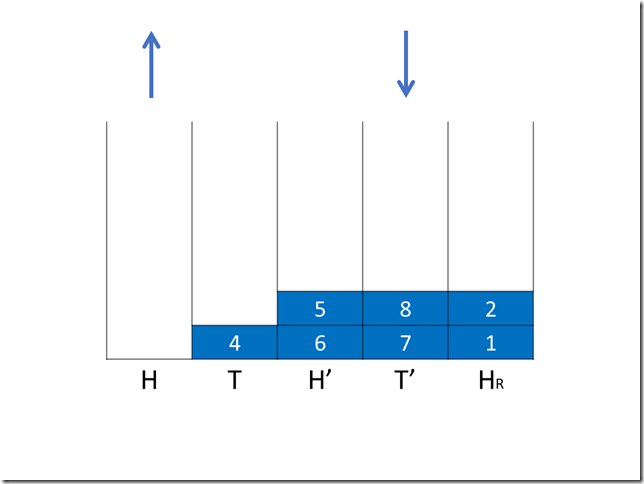
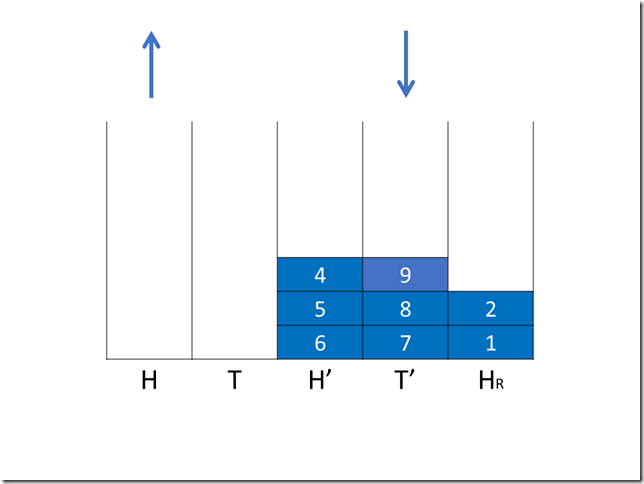
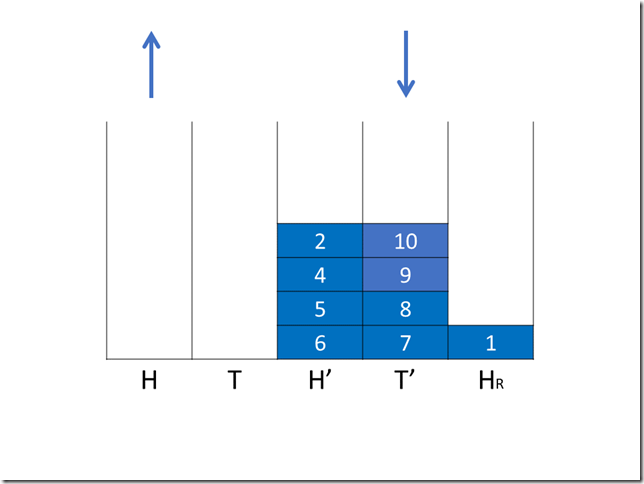
8public final int incrementAndGet() {
for (;;) {
int current = get();
int expect = current + 1;
if (compareAndSet(current, expect))
return next;
}
}
如果检测到冲突,数据更新失败,则重新开始新的一遍CAS,直至有一次数据没有冲突。
这里也能发现,如果冲突发生概率过高,函数可能会一直在循环中,效率会非常低下,应证了CAS适合在冲突发生概率不高的情况下调用。
CAS原理
CAS在底层是通过调用JNI(Java Native Interface)实现
1.oldvalue放在eax寄存器中,newvalue放在ecx中,addr(pointer)放在edx中。
2.cmpxchg指令首先比较addr指向的内存与oldvalue(eax),如果二者相等,将newvalue(ecx)放到addr所指向的内存中,同时设置Z标志1。
3.setne与andl 指令的操作的结果很简单:如果Z标志被设置,则eax为0,否则为1。程序执行最终eax放到xchg变量里。
通过底层的汇编代码给与CAS原子性,使得CAS的操作不能被分割,即在调用中值不能被其他线程修改。
CAS问题
接下去看下使用CAS出现的一些问题
ABA问题
A->B->A // 前面的A和后面A状态不一致,但是CAS无法识别
回到刚才的场景,当前线程需要将值加一,假设获取值和调用CAS中间有额外两个线程对数据都做了修改,一个线程加一,另外一个线程减一。在CAS判断是current仍旧与当前值相同,CAS的更新会生效。但是我们无法得知这中间有数据加一再减一的变化。当然在这个场景中,这不影响程序的结果,因为我们的程序设定就是将当前值并发的加一。
我们考虑再考虑一个现实场景,妈妈和爸爸为了奖励勤工俭学的孩子,发现到其银行卡账号金额等于100元就给孩子10元奖励,最多只有一位家长发放奖励。这里的CAS中current为100时,我们无法区分这两种情况:
1.孩子自己赚到100元;
2.赚到100元后其中一位父母给与10元奖励而后迅速消费掉,余额还是100元。
这时就需要使用AtomicStampedReference,可以理解成为各个状态打上stamp,在CAS判断时以stamp和值为准。1
public boolean compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp)
大家在git使用也会遇到类似问题,即使本地文件和服务端文件内容一致,中间也有可能有变更,所以git中使用文件版本号去判断文件一致性。
复合数据的CAS
在我们之前的讨论中,只针对一个共享变量的原子操作,无法同时保持多个变量的一致性。
在银行账号中,如果开通了美元账号,用户就同时有美元余额和人民币余额,必须保持两个变量的一致性。
这时候我们就需要AtomicReference去解决这个问题,这是AtomicReference的主要源码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public class AtomicReference<V> implements java.io.Serializable {
private static final long serialVersionUID = -1848883965231344442L;
// 获取Unsafe对象,Unsafe的作用是提供CAS操作
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicReference.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
// volatile类型
private volatile V value;
public final V get() {
return value;
}
public final boolean compareAndSet(V expect, V update) {
return unsafe.compareAndSwapObject(this, valueOffset, expect, update);
}
}
它是通过volatile和”Unsafe提供的CAS函数”实现原子操作。
1.value是volatile类型。这保证了当某线程修改value的值时,其他线程看到的value值都是最新的value值,即修改之后的volatile的值。
2.通过CAS设置value。这保证了当某线程池通过CAS函数(如compareAndSet函数)设置value时,它的操作是原子的,即线程在操作value时不会被中断。
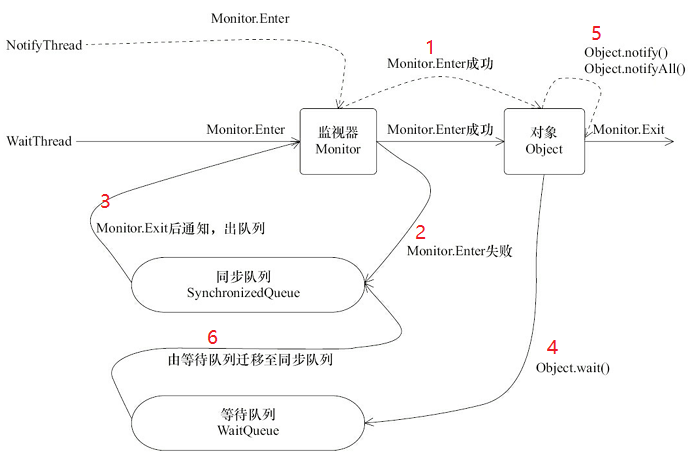
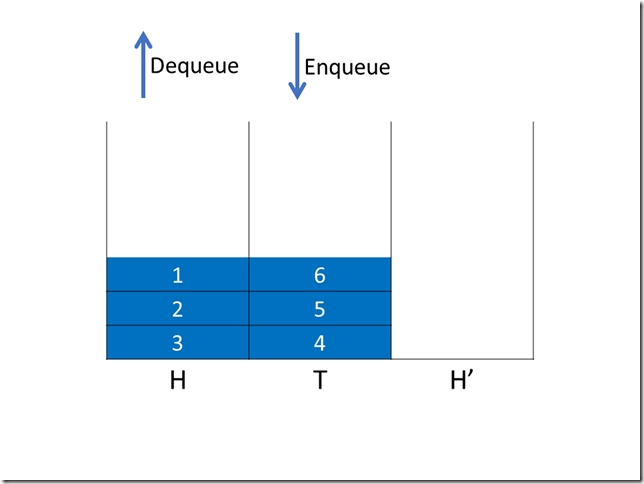
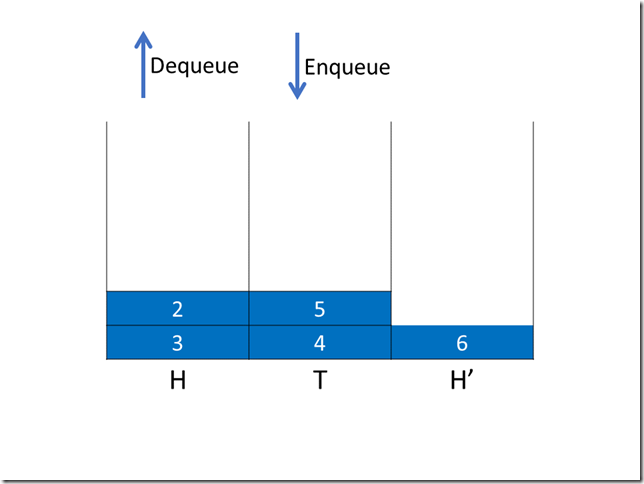
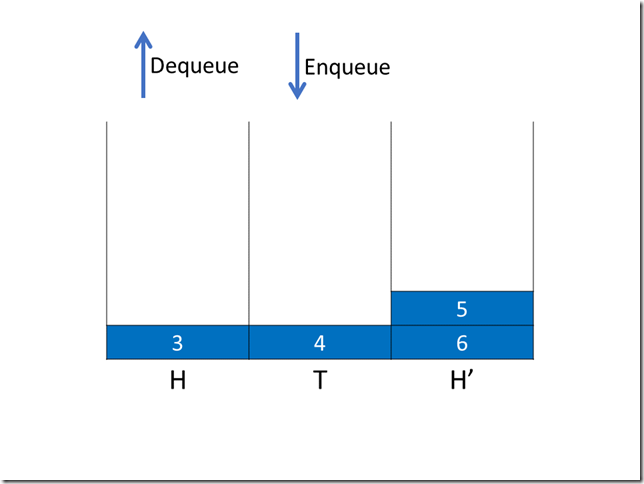
ConcurrentLinkedQueue
在java中CAS典型的使用就是ConcurrentLinkedQueue,大家有兴趣的话去看下源码,非常精简高效。
这里就简单提一下要点,Queue队列最关键处理head和tail,如果每次加锁开销会比较高,所以分别用CAS去控制更新。